vscodeのdevcontainerを利用する
開発環境を構築する際に利用する場合があります。私が以前いた場所では使っていました。OracleのDBサーバーを開発環境として構築する際にdevcontainerを使っていました
devcontainerを用意しておけばdockerのコマンドを使わなくてもコンテナの利用ができます
導入
拡張機能を入れておきます
- Dev Containers
利用する
試しにRustの開発環境を作成します
何もファイルなどがない空のフォルダをvscodeで開きます
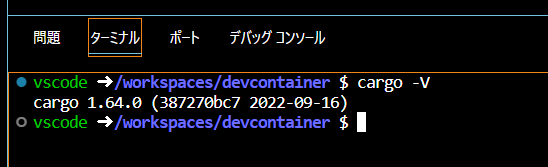
ターミナルにてcargo -Vと入力します
もしもRustの環境がマシンにない人はコマンドがないというエラーになると思います

次に画面左下の><マークをクリックして、Reopen in Containerをクリックします

そのまま検索欄にrustを入力して、Rust devcontainerをクリックします

そのまま流れでデフォルトを選択して、最後は0個を選択のままOKボタンをクリックします

するとイメージのビルドなどが行われますのでそのまま待ちます
エクスプローラーに.devcontainerフォルダが作成されます

ターミナルにてcargo -Vを入力するとコマンドが利用できることがわかります 私の場合は自身の端末より新しいバージョンであることが確認できています
つまりコンテナの環境でコマンドが実行できているのです
そのままcargo initしてcargo runするとRustの実行までできます

.devcontainerフォルダにはdevcontainer.jsonができています
{ "name": "Rust", "image": "mcr.microsoft.com/devcontainers/rust:1-buster", // Use 'forwardPorts' to make a list of ports inside the container available locally. // "forwardPorts": [], // Use 'postCreateCommand' to run commands after the container is created. // "postCreateCommand": "rustc --version", // Set `remoteUser` to `root` to connect as root instead. More info: https://aka.ms/vscode-remote/containers/non-root. "remoteUser": "vscode" }
このようにjsonファイルを元にコンテナを作成してくれるのです
自分で.devcontainerを作成する
また空フォルダを開いたら、Dockerfileを作成します
簡単にnodeを利用するだけです
FROM node:18
D:.
Dockerfile
サブフォルダーは存在しません
ただDockerfileを作っただけですね
ここまで出来たら、画面左下の><ボタンを押して今度はOpen folder in Contaierをクリックします

そして現在のフォルダを選択したら、fron Dockerfileを選択します
すると自動的に.devcontainerというフォルダとdevcontainer.jsonが作成され、コンテナが起動します
ターミナルからnode -vを実行します

Dockerfileに基づいたコンテナが作成されています
Dockerコンテナに作成したJenkinsからDockerコンテナのTomcatにwarファイルをデプロイする
以前書いた記事
DockerとJenkinsでJavaプロジェクトのコンパイル等してwarファイルのデプロイをする - Qiita
この記事ではTomcat環境をDockerコンテナで作成して、そこに同じくDockerコンテナで作成したJenkins環境からデプロイを行うということをやりました。 流れとしてはこうです
今回はMavenでやっていたのをgradleにして、Jenkinsの環境も新しく2.376で実施します。

また以前の記事では色々と省略していたので詳しく記事にしていこうと思います。
記事の流れ
- コンテナの準備
- tomcatとjenkinsのコンテナを作成します
- tomcatの設定
- ユーザーとロールの設定
- Webアプリケーションマネージャの設定
- Jenkinsの設定
- ジョブの作成
- 認証情報の作成
- パイプラインスクリプトの記載
予め対象となるソースはGitHubにアップロードしておきます。
コンテナの準備
以下のフォルダ構成でファイルを準備します。
D:.
│ docker-compose.yaml
│
├─jenkins
│ └─data
└─tomcat
Dockerfile
Dockerfile
FROM tomcat:9.0 RUN apt-get update && apt-get install -y wget && apt-get install -y vim
Docker-compose.yaml
version: '3' services: tomcat: build: context: . dockerfile: ./tomcat/Dockerfile container_name: tomcat privileged: true ports: - "8012:8080" volumes: - "./tomcat/data:/var" tty: true jenkins: container_name: jenkins image: jenkins/jenkins:alpine ports: - "8888:8080" volumes: - "./jenkins/data:/var/jenkins_home" tty: true
コンテナを立ち上げます
docker-compose up -d
D:\docker\tomcatjenkins>docker-compose up -d Docker Compose is now in the Docker CLI, try `docker compose up` Creating network "tomcatjenkins_default" with the default driver Building tomcat [+] Building 9.6s (6/6) FINISHED => [internal] load build definition from Dockerfile 0.1s => => transferring dockerfile: 125B 0.0s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [internal] load metadata for docker.io/library/tomcat:9.0 0.0s => [1/2] FROM docker.io/library/tomcat:9.0 0.1s => [2/2] RUN apt-get update && apt-get install -y wget && apt-get install -y vim 9.1s => exporting to image 0.4s => => exporting layers 0.4s => => writing image sha256:56eab31fdeaae33f66468f60f0970fec539bb430f7ed6e2d478e3252bb8e9331 0.0s => => naming to docker.io/library/tomcatjenkins_tomcat 0.0s WARNING: Image for service tomcat was built because it did not already exist. To rebuild this image you must use `docker-compose build` or `docker-compose up --build`. Creating tomcat ... done Creating jenkins ... done D:\docker\tomcatjenkins>
Tomcatの設定
ユーザーとロールを追加しておきます tomcat-users.xmlというファイルを修正します。Tomcatコンテナに入って直接修正します。 vimは事前にインストール済ですので利用可能です。
D:\docker\tomcatjenkins>docker exec -it tomcat bash root@03442bc6f07e:/usr/local/tomcat# root@03442bc6f07e:/usr/local/tomcat# find / -name tomcat-users.xml /usr/local/tomcat/conf/tomcat-users.xml root@03442bc6f07e:/usr/local/tomcat# vim /usr/local/tomcat/conf/tomcat-users.xml root@03442bc6f07e:/usr/local/tomcat#
ファイルの最後の方に以下を追加しておきます
<role rolename="manager-gui"/> <role rolename="admin-gui"/> <role rolename="manager-script"/> <user username="misaka" password="password" roles="manager-gui,admin-gui,manager-script"/> </tomcat-users>
現状のwebappsフォルダには何もありません。
root@03442bc6f07e:/usr/local/tomcat# ls BUILDING.txt CONTRIBUTING.md LICENSE NOTICE README.md RELEASE-NOTES RUNNING.txt bin conf lib logs native-jni-lib temp webapps webapps.dist work root@03442bc6f07e:/usr/local/tomcat# cd webapps root@03442bc6f07e:/usr/local/tomcat/webapps# ls root@03442bc6f07e:/usr/local/tomcat/webapps#
webapps.distフォルダには色々入っているので必要であればコピーすることで利用可能です。
root@03442bc6f07e:/usr/local/tomcat# cd webapps.dist root@03442bc6f07e:/usr/local/tomcat/webapps.dist# ls ROOT docs examples host-manager manager
webapps.distのmanagerをwebappsにコピーします
root@03442bc6f07e:/usr/local/tomcat# cp -r webapps.dist/manager webapps root@03442bc6f07e:/usr/local/tomcat# root@03442bc6f07e:/usr/local/tomcat# ls webapps manager
そして許可するIPアドレスを修正します。(全てのIPアドレスを許可するように修正)
root@03442bc6f07e:/usr/local/tomcat# find ./ -name context.xml ./conf/context.xml ./webapps/manager/META-INF/context.xml ./webapps.dist/manager/META-INF/context.xml ./webapps.dist/examples/META-INF/context.xml ./webapps.dist/host-manager/META-INF/context.xml root@03442bc6f07e:/usr/local/tomcat# root@03442bc6f07e:/usr/local/tomcat# vim ./webapps/manager/META-INF/context.xml
以下のようにallowとなっている部分のValveをコメントアウトします
<!-- <Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="127\.\d+\.\d+\.\d+|::1|0:0:0:0:0:0:0:1" /> --> <Manager sessionAttributeValueClassNameFilter="java\.lang\.(?:Boolean|Integer|Long|Number|String)|org\.apache\.catalina\.filters\.CsrfPreventionFilter\$LruCache(?:\$1)?|java\.util\.(?:Linked)?HashMap"/> </Context>
この2つをやらないと/managerにアクセスした時に403エラーが返ってきます
Jenkinsの設定
次にJenkinsの設定を行います。 コンテナは立ち上がっている状態なので、以下にアクセスします
初期設定が必要になります
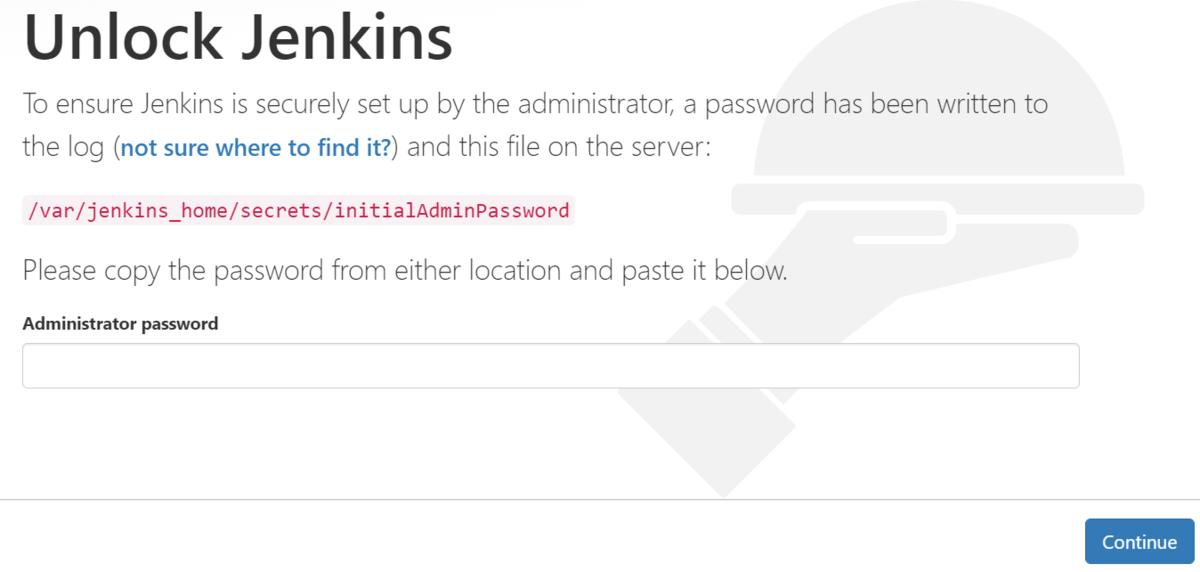
パスワードを/var/jenkins_home/secrets/initialAdminPasswordから取得して入力する必要があります。
コンテナに入ってcatコマンドを実行してもいいですが、コンテナに入らずに実行します。 execコマンドにコンテナ名とコマンドを渡してあげます
D:\docker\tomcatjenkins>docker exec jenkins cat /var/jenkins_home/secrets/initialAdminPassword df8b97707cea464face45e640f0abfe7
ここで取得したキーを入力します
オススメのプラグインをインストールするをクリック(左)して、初期設定を行います。
ここで古いJenkinsを利用しているとプラグインのインストールに失敗するようです。 私は2.303でエラーになりました。 と思ってlatestを利用しても同じようなエラー。迷っていると以下の記事に遭遇しました
Jenkinsのdockerイメージは、Docker公式とJenkins公式の2つあるのか… - 新しいことにはウェルカム なるほど。。
任意のユーザーを作成してJenkinsの開始を行います。
Deploy to container プラグインのインストール
Deploy to containerというプラグインをインストールします
Jenkinsの管理 > プラグインマネージャー > 利用可能
検索ワードに「Deploy to container」と入力

installにチェックを入れてinstall without restartを押します
パイプラインジョブの作成
パイプラインジョブを任意の名前で作成したら、GitHub projectにチェックを入れてURLを指定します。 一旦これだけの設定で保存しておきます

次のジョブの画面からPipeline Syntaxをクリックします。
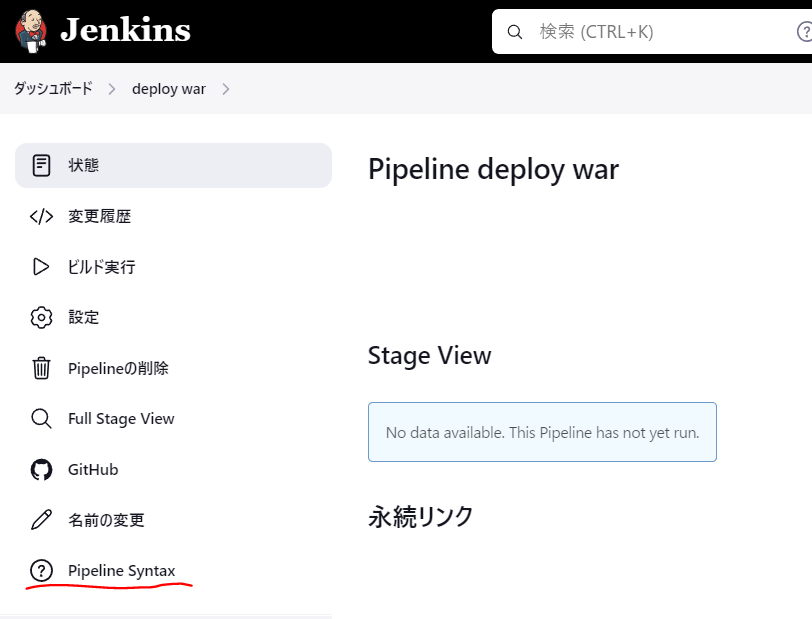
ContainersにTomcat9.x Remoteを選択して、Credentialsの追加を押下します

認証情報の追加でDomainを「グローバルドメイン」を選択して、種類に「ユーザー名とパスワード」を選択します。
ここではtomcatで作成したユーザーとパスワードを指定します。IDは任意のものを入力して追加ボタンを押下します

その後、ContainersのCredentialsに追加した認証情報を指定します
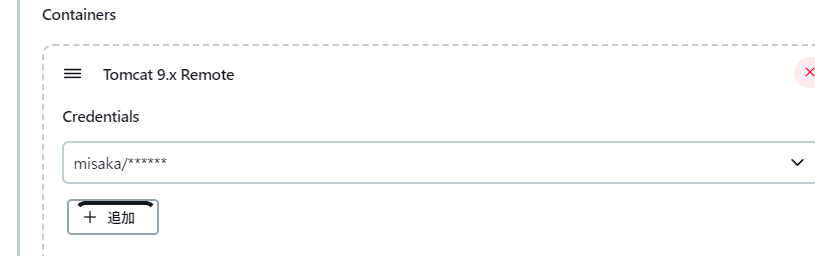
このTomcatのURLはコンテナのIPアドレスと、そのコンテナで動いているTomcatのポート番号を指定します
→ 今回の場合ホスト側でアクセスする時のアドレスではないことに気を付けてください
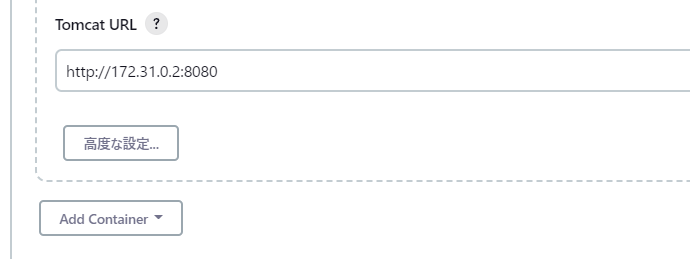
TomcatのURLを入力したらGenerate Pipeline Scriptボタンを押します。
このスクリプトはデプロイステージで利用しますのでメモしておきます。
deploy adapters: [tomcat9(credentialsId: 'tomcat_misaka', path: '', url: 'http://172.31.0.2:8080')], contextPath: null, war: '**/*.war'
ジョブの画面から設定を押してジョブの修正を行います。

設定画面の下にパイプラインという項目を修正します。
定義に「Pipeline script」を選択します
以下のコードを入力します
pipeline {
agent any
options {
skipStagesAfterUnstable()
}
stages {
stage('Build') {
steps {
echo 'Start gradle Build..'
checkout([$class: 'GitSCM', branches: [[name: '*/main']],
userRemoteConfigs: [[url: 'https://github.com/jirentaicho/jenkins-test']]])
sh 'chmod +x gradlew'
sh './gradlew build'
echo 'Deploy..'
deploy adapters: [tomcat9(credentialsId: 'tomcat_misaka', path: '', url: 'http://172.31.0.2:8080')], contextPath: null, war: '**/*.war'
}
}
}
}
deploy adapters: の部分はgenerateで出力したコードの部分です。 どの認証情報で、どのパスに、どのwarファイルをデプロイするかを指定しています。
gradle buildを行うと一通り実行してくれるのでbuildだけを行っています
実行して正常に終了してくれるのを待ちます

成功すると緑色で、失敗すると赤色で表示されます。 もし失敗した場合はログを確認します。
ビルド履歴の#番号の個所をクリックします

Console Outputを押すと実行ログがを見ることができます

これは接続拒否されていました。 →原因はポート番号に誤りがありました。
他にもURLが間違っているとTimeoutになっていたりします。
成功してTomcatのWebアプリケーションマネージャを利用するとデプロイができていることがわかります

またアプリケーションも確認します

テストの失敗
失敗するテストケースをgithubにpushしてjenkinsを動かしてみます。 gradleのtestで失敗するはずです。
@Test public void test_fail(){ assertTrue(false); }
予想通り失敗しています
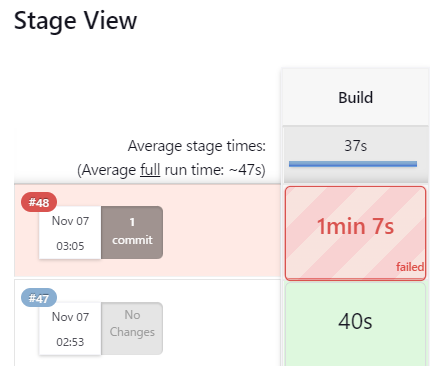
詳細のログを確認してみます

テストで失敗してることがわかります。
おまけ
docker-composeでコンテナの停止から削除
D:\docker\tomcatjenkins>docker-compose stop jenkins Stopping jenkins ... done D:\docker\tomcatjenkins>docker-compose rm jenkins Going to remove jenkins Are you sure? [yN] y Removing jenkins ... done
Javaのイマジナリージェネリクス
ModelMapperにある、とある処理
private <D> D mapInternal(Object source, D destination, Type destinationType, String typeMapName) { if (destination != null) destinationType = Types.<D>deProxy(destination.getClass()); return engine.<Object, D>map(source, Types.<Object>deProxy(source.getClass()), destination, TypeToken.<D>of(destinationType), typeMapName); }
ライブラリなので知る必要は無い箇所だが、とても難しそうなジェネリクスを使った処理になっている
呼び出し元
public <D> D map(Object source, Class<D> destinationType) { Assert.notNull(source, "source"); Assert.notNull(destinationType, "destinationType"); return mapInternal(source, null, destinationType, null); }
利用例
Game game = new Game("スプラ3"); ModelMapper modelmapper = new ModelMapper(); GameDto gameDto = modelmapper.map(game,GameDto.class);
この場合はDというのは何なのか?を特定するのが理解の第一歩です
例えば、少しマジカルな印象だがClassクラスの定義はClass<T>なので何らかの型を指定できる
public final class Class<T> implements java.io.Serializable, GenericDeclaration, Type, AnnotatedElement, TypeDescriptor.OfField<Class<?>>, Constable {
なのでClass<D>のDを返すというのは、D型の事を指している
ものすごく単純なClass<D>のD型のオブジェクトを返す処理を書きました
private <D> D get(Class<D> clazz) throws Exception { // コンストラクタの取得 Constructor<D> constructor = clazz.getConstructor(); D obj = constructor.newInstance(); return obj; }
このDというのはClass<D>のDなので、Dの実際のインスタンスを返すことになる。
GameDto gameDto = null; try { gameDto = get(GameDto.class); gameDto.name = "リフレクションで取得したインスタンス"; } catch (Exception exception) { exception.printStackTrace(); } assertEquals("リフレクションで取得したインスタンス",gameDto.name);
Classクラスを返すのでなく、その型のオブジェクトを返すというのが重要なポイントです
例えば次はわかりやすいです
private <T> T get(List<T> list){ return list.get(0); }
このメソッドが返すのはListでなくて、Listに紐づくT型のインスタンスです
List<GameDto> list = List.of(new GameDto()); GameDto dto = this.get(list); dto.name = "スプラ"; assertEquals("スプラ",dto.name);
本題に戻りまして...
ModelMapperの以下の処理は、Class<D>、つまりD型のインスタンスを返すことになります
public <D> D map(Object source, Class<D> destinationType) { Assert.notNull(source, "source"); Assert.notNull(destinationType, "destinationType"); return mapInternal(source, null, destinationType, null); }
その中で一番最初に掲載したコードに行き着くわけですが、引数のdestinationはnullが渡っています。 (今回の場合)
private <D> D mapInternal(Object source, D destination, Type destinationType, String typeMapName) { if (destination != null) destinationType = Types.<D>deProxy(destination.getClass()); return engine.<Object, D>map(source, Types.<Object>deProxy(source.getClass()), destination, TypeToken.<D>of(destinationType), typeMapName); }
なので注目すべきはreturn節です。
""
ここでTypeToken.<D>of(destinationType)というコードでmapメソッドの引数に渡しています。destinationTypeはクラスオブジェクトです。
このofは引数のType情報に基づいてTypeTokeという型のインスタンスを返します。TypeTokeは、rawType変数としてClassオブジェクトを管理しています。→ここにdestinationTypeが入ります。
""
""で囲った内容は少し複雑です。重要な考えはmapInternalメソッドで受け取るD destinationがnullなのに、engine.<Object, D>mapとして返却できるということです。
この動きを簡単に確認してみます。
public class MyTypeToken<T> { private Class<T> clazz; public static <T> MyTypeToken<T> of(Type type) throws Exception { return new MyTypeToken<T>(type); } private MyTypeToken(Type t) throws Exception{ // キャストしてあげる Class<T> clazz = (Class<T>) t; this.clazz = clazz; } public Class<T> getClazz(){ return this.clazz; } }
このクラスは受け取ったTをClass<T>として保持します そのためにTypeをキャストしています。 →未検査警告が出ると思います。
今作ったMyTypeTokenを利用してジェネリクスで指定されている型を受け取らずに結果を返せるメソッドを定義します
private <D> D getD(D clazz, Type type){ // clazzがnullでも、戻り値を特定できる D result = null; try { MyTypeToken token = MyTypeToken.<D>of(type); Class<D> d = token.getClazz(); Constructor con = d.getConstructor(); result = (D) con.newInstance(); } catch (Exception e){ } return result; }
このメソッドは<D>としてMyTypeTokenのオブジェクトを生成します。 そしてDのインスタンスはMyTypeTokenに格納されているClass<T> clazzから生成します
このメソッドをDの指定をせずに呼び出します
GameDto g = this.getD(null,GameDto.class); g.name = "wow"; System.out.println(g.name); assertEquals("wow",g.name);
このテストは成功します。つまりGameDtoのインスタンスがgetDメソッドを介して取得できています。 これは奇妙でイマジナリーなジェネリクスの動きを検証しました。
ここまでくると以下の処理も追いつけると思います
return engine.<Object, D>map(source, Types.<Object>deProxy(source.getClass()), destination,
TypeToken.<D>of(destinationType), typeMapName);
コードリーディング FileUtils.readFileToString
コードを読んで勉強する目的
今回のターゲットはFileUtils.readFileToStringです
FileUtils.readFileToStringメソッドの引数を見ると
public static String readFileToString(final File file, final Charset charsetName) throws IOException { try (InputStream inputStream = openInputStream(file)) { return IOUtils.toString(inputStream, Charsets.toCharset(charsetName)); } }
Fileオブジェクトを受け取る必要がありますので、以下のように利用します
try { String result = FileUtils.readFileToString(Paths.get("D:\\sumomo\\sumomon.txt").toFile(), Charset.forName("UTF-8")); System.out.println(result); } catch (IOException e) { e.printStackTrace(); }
または以下のようなFileクラスを使う方法です
try { String result = FileUtils.readFileToString(new File("D:\\sumomo\\sumomon.txt"), Charset.forName("UTF-8")); System.out.println(result); } catch (IOException e) { e.printStackTrace(); }
おそらくこのFileクラスのオブジェクトを受け取るのが想定された方法なのでしょうが、java.io.Fileは使われることが少なくなりました。 しかし古くからあるためjava.nioとの相互変換も可能です。
このコードはテキストファイルの中身をStirngで受け取り、コンソールに出力しています。
ソースコード
実装は以下のようになっている
public static String readFileToString(final File file, final Charset charsetName) throws IOException { try (InputStream inputStream = openInputStream(file)) { return IOUtils.toString(inputStream, Charsets.toCharset(charsetName)); } }
- try-with-resourcesを使って安全にcloseされます
- 更に別のIOUtilsというクラスを利用しています
渡したFileオブジェクトはopenInputStreamメソッドに渡っています。
public static FileInputStream openInputStream(final File file) throws IOException { Objects.requireNonNull(file, "file"); return new FileInputStream(file); }
- Fileのnullチェックを行う
- FileInputStreamオブジェクトを返す
ちなみに
InputStreamで文字列を出力する時は、readメソッドの引数に渡したバイト配列をSystem.out.writeなどで出力します。
文字列ストリームを扱う場合はInputStreamをInputStreamReaderのコンストラクタに渡します
IOUtils.toStringメソッド
public static String toString(final InputStream input, final Charset charset) throws IOException { try (final StringBuilderWriter sw = new StringBuilderWriter()) { copy(input, sw, charset); return sw.toString(); } }
StringBuilderWriterというWriterのサブクラスを利用しています。 これはorg.apache.commons.io.outputパッケージにあります
先ほども書いたようにInputStreamReaderで文字IOストリームを扱えます。このクラスはReaderクラスのサブクラスで、Writerというのも同じ立ち位置です。 なのでWriterのサブクラスということは文字IOストリームを扱うためのサブクラスだと認識できます。
copyメソッド
public static void copy(final InputStream input, final Writer writer, final Charset inputCharset) throws IOException { final InputStreamReader reader = new InputStreamReader(input, Charsets.toCharset(inputCharset)); copy(reader, writer); }
文字IOストリームを扱うためのInputStreamReaderを生成しています。 ここまでほぼ以下のコードと変わりません
FileInputStream fileInputStream = new FileInputStream("file.txt"); InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "UTF8");
このメソッドは戻り値の無いvoid型であることに注意します。 IOUtils.toStringメソッドを見て推測すると、Writerオブジェクトに対してファイルの内容を付与していると思われます。
そして引数の違う次のcopyメソッドです
public static int copy(final Reader reader, final Writer writer) throws IOException { final long count = copyLarge(reader, writer); if (count > Integer.MAX_VALUE) { return EOF; } return (int) count; }
このメソッドのjavadocを見ると
Copies chars from a Reader to a Writer. This method buffers the input internally, so there is no need to use a BufferedReader. Large streams (over 2GB) will return a chars copied value of -1 after the copy has completed since the correct number of chars cannot be returned as an int. For large streams use the copyLarge(Reader, Writer) method.
とあります。 やはりReader→Writerへと文字列のコピーを行うようです。 大きな文字を扱う場合はcopyLargeメソッドを使ってくださいと注意書きがありますが、内部的にはcopyLargeメソッドを使っているようです??
public static long copyLarge(final Reader reader, final Writer writer, final char[] buffer) throws IOException { long count = 0; int n; while (EOF != (n = reader.read(buffer))) { writer.write(buffer, 0, n); count += n; } return count; }
ここでreader.readメソッドを利用します。 これは配列に文字を読み込みます。そしてストリームの終端に達すると-1を返します。 読み込んだ配列をWriter.writeに渡して書き込んでいます
このwriteメソッドはStringBuilderWriterで実装が以下のようになっています
@Override public void write(final char[] value, final int offset, final int length) { if (value != null) { builder.append(value, offset, length); } }
StringBuilderに対して文字列を加えていっているというシンプルな構造です。 そして読み込んだテキストを最終的に文字列として返しているのがtoStringメソッドです
@Override public String toString() { return builder.toString(); }
StringBuilderのtoStringを呼び出しているだけです。
ソースを読むと、上手に面倒な処理が隠蔽されていることがわかります。 もちろんこのクラスが利用しているのはjava.ioパッケージなので、nioを使ってもっとシンプルに扱うこともできます。
JavaのCollectionUtils.getCardinalityMapを少しだけ速くする
CollectionUtils.getCardinalityMapこのメソッドは面白いです。
イテレート可能なオブジェクトの要素を全てkeyにしたMapを作ります。 このMapのvalueは数値の1です。keyが重複した場合はvalueをインクリメントさせます
以下のテストで動きを確認します
@Test public void test_get_countmap(){ List<String> strs = List.of("abc","def","ghi","abc"); Map<Object, Integer> count = CollectionUtils.getCardinalityMap(strs); assertEquals(count.get("abc"),2); assertEquals(count.get("ghi"),1); assertEquals(count.size(),3); }
ちなみに実装は以下のコードです
public static <O> Map<O, Integer> getCardinalityMap(final Iterable<? extends O> coll) { final Map<O, Integer> count = new HashMap<>(); for (final O obj : coll) { final Integer c = count.get(obj); if (c == null) { count.put(obj, Integer.valueOf(1)); } else { count.put(obj, Integer.valueOf(c.intValue() + 1)); } } return count; }
果たしてこれを改造するとしたらどうでしょうか そもそもこのコードはそこまで改造する必要はありません あえて言うならば、最初のcount.get(obj)以降動きが、if文を読むまでは理解できないことくらいでしょうか。 この場合はメソッド抽出でもできればキレイになりますが、Utilクラスにそんなことまで求めるのはナンセンスかもしれません。
無理矢理コードを書きました
public static <T> Map<T,Integer> getCardinalityMap(final Iterable<? extends T> coll){ final Map<T, Integer> count = new HashMap<>(); coll.forEach(item -> { final Integer c = count.get(item); if (c == null) { count.put(item, Integer.valueOf(1)); } else { count.put(item, Integer.valueOf(c.intValue() + 1)); } }); return count; }
foreachを使っているのに元々のメソッドとほとんど何も変わっているように見えません。 ここでメソッド抽出をして少しでもわかるように修正します
public static <T> Map<T,Integer> getCardinalityMap(final Iterable<? extends T> coll){ final Map<T, Integer> count = new HashMap<>(); coll.forEach(item -> { count.put(item, getCardinalityValue(item,count)); }); return count; } private static <T> int getCardinalityValue(T item, Map<T,Integer> count){ final Integer c = count.get(item); if (c == null) { return 1; } else { return Integer.valueOf(c.intValue() + 1); } }
countにputしているのはCardinalityな値なのねというのは抽象的に理解できるようになりました
速度が少しだけ早くなります。 また大量のオブジェクトを突っ込む処理を行って単純な速度を比較します
@Test public void test_count(){ class Item{ public final int id; public final String name; public Item(int id, String name){ this.id = id; this.name = name; } } // 大量のオブジェクトを仕込む List<Item> lista = new ArrayList<>(); for(int i = 0; i < 300000; i++){ Item item = new Item(i,"商品" + String.valueOf(i)); lista.add(item); } long startTime = System.currentTimeMillis(); Map<Object, Integer> counta = CollectionUtils.getCardinalityMap(lista); long endTime = System.currentTimeMillis(); System.out.println("処理時間:" + (endTime - startTime) + " ms"); startTime = System.currentTimeMillis(); Map<Object, Integer> countb = MyCollectionUtils.getCardinalityMap(lista); endTime = System.currentTimeMillis(); System.out.println("処理時間:" + (endTime - startTime) + " ms"); }
◆1回目 処理時間:100 ms 処理時間:60 ms
◆2回目 処理時間:110 ms 処理時間:80 ms
◆3回目 処理時間:110 ms 処理時間:72 ms
◆4回目 処理時間:105 ms 処理時間:75 ms
◆5回目 処理時間:116 ms 処理時間:83 ms
◆6回目 処理時間:100 ms 処理時間:80 ms
◆7回目 処理時間:105 ms 処理時間:71 ms
何度か実施しましたが、どれも既存の処理よりも速度が遅くなるということはありませんでした。
JavaのCollectionUtils.containsAllをstreamと遅延処理で見直す
CollectionUtils.containsAllは一つでも要素が存在しない場合はfalseを返します
@Test public void test_all_contains(){ List<String> lista = List.of("abc","def","hij"); List<String> listb = List.of("abc","def","ghi"); boolean result = CollectionUtils.containsAll(lista,listb); assertFalse(result); List<String> listc = List.of("abc","def","ghi"); result = CollectionUtils.containsAll(listb,listc); assertTrue(result); }
CollectionUtils.containsAllの実装は以下のようになっている
public static boolean containsAll(final Collection<?> coll1, final Collection<?> coll2) { if (coll2.isEmpty()) { return true; } final Iterator<?> it = coll1.iterator(); final Set<Object> elementsAlreadySeen = new HashSet<>(); for (final Object nextElement : coll2) { if (elementsAlreadySeen.contains(nextElement)) { continue; } boolean foundCurrentElement = false; while (it.hasNext()) { final Object p = it.next(); elementsAlreadySeen.add(p); if (nextElement == null ? p == null : nextElement.equals(p)) { foundCurrentElement = true; break; } } if (!foundCurrentElement) { return false; } } return true; }
一度見つかった要素に関してはelementsAlreadySeenに入るので要素の数までは見ていません。 そのため以下のようなコードはtrueです
@Test public void test_all_contains_(){ List<String> lista = new ArrayList<>(); lista.add(null); lista.add(null); lista.add(null); lista.add("abc"); lista.add("abc"); lista.add("abc"); List<String> listb = new ArrayList<>(); listb.add(null); listb.add("abc"); boolean result = CollectionUtils.containsAll(lista,listb); assertTrue(result); }
しかしこのコードはifもforもwhileも使っているので頭が痛くなりますね
以下のように修正してみましょう。
public static boolean containsAll(final Collection<?> cola ,final Collection<?> colb){ long result = cola.stream().filter( a -> !colb.contains(a)).count(); if(result >= 1){ return false; } return true; }
これでテストしても機能として通っています
しかし処理時間に関しては疑問が残りますよね? 以下のテストで簡易的に実行時間差を見てみます
@Test public void test_perf(){ class Item{ public final int id; public final String name; public Item(int id, String name){ this.id = id; this.name = name; } } List<Item> lista = new ArrayList<>(); List<Item> listb = new ArrayList<>(); // 超絶大量のインスタンス for(int i = 0; i < 30000; i++){ Item item = new Item(i,"商品" + String.valueOf(i)); lista.add(item); listb.add(item); // これは別のインスタンスなので調査不可能 // lista.add(new Item(i,"商品" + String.valueOf(i))); // listb.add(new Item(i,"商品" + String.valueOf(i))); } long startTime = System.currentTimeMillis(); boolean result = CollectionUtils.containsAll(lista,listb); assertTrue(result); long endTime = System.currentTimeMillis(); System.out.println("処理時間:" + (endTime - startTime) + " ms"); startTime = System.currentTimeMillis(); boolean myresult = MyMapUtils.containsAll(lista,listb); endTime = System.currentTimeMillis(); System.out.println("処理時間:" + (endTime - startTime) + " ms"); assertTrue(myresult); }
計測した時間は大差がついてます
処理時間:25 ms 処理時間:908 ms
これはfilterの中で他のコレクションにアクセスしているため遅くなっています(遅くなっていると思います) Setに詰め替えることでこれは解決できます
public static boolean containsAll(final Collection<?> cola ,final Collection<?> colb){ Set<?> set = new HashSet<>(colb); long result = cola.stream().filter( a -> !set.contains(a)).count(); if(result >= 1){ return false; } return true; }
処理時間:26 ms 処理時間:5 ms
圧倒的なパフォーマンスの差を出しました。
しかしまだです。まだ、パフォーマンスで負ける可能性があります これは全て走査するので無駄な処理が走ってしまいます 元々は1件でもあればその時点でfalseが返却されるのと、elementsAlreadySeenのようなtemp変数が用意されているため速いです
以下のコードでテストしてみます
@Test public void test_perf(){ class Item{ public final int id; public final String name; public Item(int id, String name){ this.id = id; this.name = name; } } List<Item> lista = new ArrayList<>(); List<Item> listb = new ArrayList<>(); // 件数を増やす30000→300000 for(int i = 0; i < 300000; i++){ Item item = new Item(i,"商品" + String.valueOf(i)); lista.add(item); // listbにだけ違うデータを仕込む if(i == 3){ listb.add(new Item(999999,"ダミー")); continue; } listb.add(item); } long startTime = System.currentTimeMillis(); boolean result = CollectionUtils.containsAll(lista,listb); assertFalse(result); long endTime = System.currentTimeMillis(); System.out.println("処理時間:" + (endTime - startTime) + " ms"); startTime = System.currentTimeMillis(); boolean myresult = MyMapUtils.containsAll(lista,listb); endTime = System.currentTimeMillis(); System.out.println("処理時間:" + (endTime - startTime) + " ms"); assertFalse(myresult); }
処理時間:104 ms 処理時間:76 ms
まだ速度で負けてないのですが、その差が縮まっています。
というわけで更に改善します。 これはstreamの遅延処理を使っています
public static boolean containsAll(final Collection<?> cola ,final Collection<?> colb){ Set<?> set = new HashSet<>(colb); return cola.stream().filter( a -> !set.contains(a)).findFirst().isEmpty(); }
処理時間:98 ms 処理時間:34 ms
圧倒的な速さです。
これはなぜでしょうか?
実はfilterメソッドは一度に全ての要素を検索するわけではありません。 まずfilterで要素が見つかった場合は、次のチェーンへと処理を渡します。 今回の場合はfindFirstメソッドです。これは最初の1件を返すメソッドです。
このfindFirstは終端処理であり、ここで終了条件を満たすとチェーンはそこで終了します。 そのため、もしもfilterで要素が見つかると、findFistで終了条件が満たされ処理終了します。 filterは最後まで処理を行うことをしません。これが遅延処理です。
最初はcount関数を使っていたため、終端処理で処理が終了しません(終了するのに必要な要素が取得できていない)ので、終端処理が次の要素を求めます。 そこで処理がfilterに戻ってきてノロノロと処理を続けていたのです。 streamを使うと読みやすさだけでなくパフォーマンスも改善されるということが分かったかと思います。
※計測は必ずしも正確ではありません。あくまで目安程度です。
おまけ
List.ofでリストを作る時にnullを渡すとぬるぽになるので注意
List<String> listc = List.of("aa,", null);
java.lang.NullPointerException
JavaのLinkedHashMapの要素順序を反転させる
Mapのkeyとvalueを反転させるにはMapUtilsのinvertMapを使います
Map<String,String> mapA = new HashMap<>(); mapA.put("keyA","valueA"); mapA.put("keyB","valueB"); mapA.put("keyC","valueC"); Map<String,String> invMap = MapUtils.invertMap(mapA);
では要素の並びを反転させるにはどうしたらいいでしょうか まずJavaではLinkedHashMapを使うことで要素を追加した順番を担保できます
というわけでMapの要素を逆順にするコードを書きました
public static <T,R> Map<T,R> reverse(Map<T,R> map){ List<T> mapmapper = map.keySet().stream().collect(Collectors.toList()); Collections.reverse(mapmapper); return mapmapper .stream() .collect(Collectors.toMap( k -> k, k -> map.get(k), (k, v) -> v, LinkedHashMap::new)); }
やり方は色々あると思いますが、最初にkeyだけの逆順リストを作成します。 あとはそれを順番に回して新しいLinkedHashMapを作成するという単純な処理です。
HashMapだと勝手にソートされたりします。
これをテストしてみます
@Test public void test_mycollectionutils_reversemap() { Map<String, String> mapA = new LinkedHashMap<>(); mapA.put("keyA", "valueA"); mapA.put("keyB", "valueB"); mapA.put("keyC", "valueC"); mapA.put("keyE", "valueE"); mapA.put("keyD", "valueD"); Map<String, String> reMap = MyMapUtils.reverse(mapA); List<String> keys = reMap.keySet().stream().collect(Collectors.toList()); assertEquals("keyD",keys.get(0)); assertEquals("keyE",keys.get(1)); assertEquals("keyC",keys.get(2)); assertEquals("keyB",keys.get(3)); assertEquals("keyA",keys.get(4)); }
わかりやすくEとDは元々順番が揃っていないようにしています